Overview¶
This chapter gives the overall path and reading order.
Use the mini-TOC on the right; click any item in “Recommended Reading Order” to jump to its section.
0. Recommended Reading Order¶
- Robot Management Platform (What / Why) — background & goals
- From Monolith to Microservices — migration strategy & boundaries
- Architecture Overview — components & trade-offs
- Project Phases & Milestones — break big goals into small steps
- OpenAPI Wrapping & Stability Governance — interface governance & resilience
- Service Level Objectives (SLO) — target metrics & continuous improvement
1. Robot Management Platform (What / Why)¶
What
- A unified entry for multiple vendors’ robots (cleaning, patrol, delivery, etc.).
- Normalize vendor OpenAPIs; provide orchestration, scheduling, monitoring, and safety guards.
Why
- Integration pain: different auth/signing, request/response formats, error semantics.
- Stability: rate-limits, retries, backoff, circuit-breakers, graceful degradation.
- Ops: full-link tracing, metrics, logs; issue → root cause → fix loop.
- Delivery: one-click multi-env delivery with Docker Compose.
2. From Monolith to Microservices¶
Summary¶
| Module | Key points |
|---|---|
| Background / Pain | Monolith validated quickly; as scale grew, releases had a wide blast radius and configs became scattered. |
| Goal | Smooth migration with near-zero UX impact; minute-level rollback. |
| Key Design | Gateway: /external/gs/**; Nacos: registry/config (multi-env); Docker Compose: one-click multi-container delivery. |
| Trade-offs | DTOs extracted to ruoyi-api-robot; controllers slimmed; logic pushed down to GsOpenApiServiceImpl. |
Metrics & Results¶
| Metric | Target / Baseline | Notes |
|---|---|---|
| Cold start → ready | ≤ 12 min | Compose (incl. first-run SQL) to bring up a fresh environment. |
| Rollback time | ≤ 5 min | Minute-level rollback after the split. |
| p95 latency | ≈ 6 ms | Baseline 100 QPS (Dry-Run); P99 ≈ 9–10 ms; Error=0. |
| Release window | Shorter | Impact scope shrinks after splitting services. |
| One-click delivery | Compose + volumes + first-run SQL | Fresh env ready ≤ 12 min. |
Retro¶
- Ship first, evolve later; unify resource names / rules / error body / log fields.
3. Architecture Overview¶
Shape: RuoYi-Cloud microservices (Gateway + business), Nacos for registry/config, RabbitMQ for async (see the Async page), MySQL/Redis for data & cache, SkyWalking for observability loop, Nginx for static frontends.
1) System Diagram¶
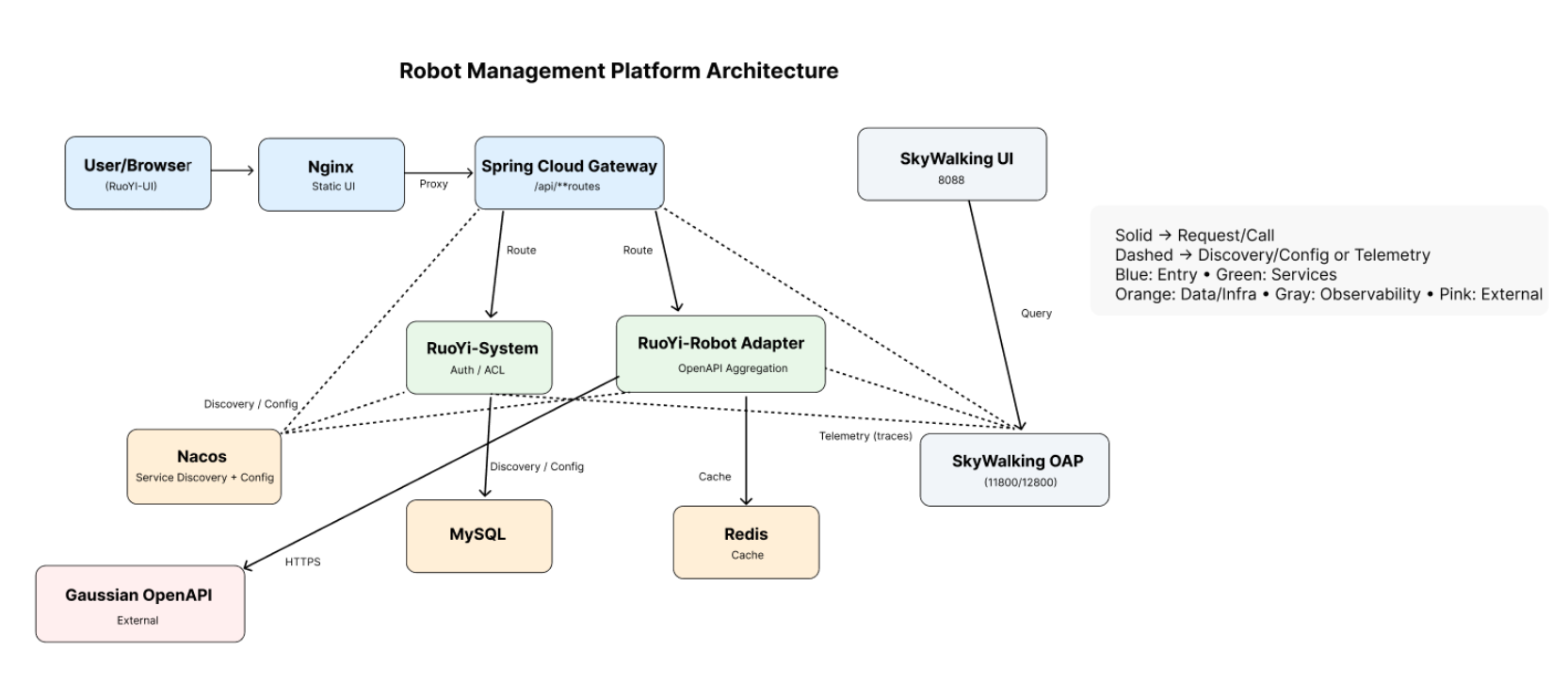
Relations
- Ingress: User/Browser → Nginx → Spring Cloud Gateway (/api/** routes)
- Business: RuoYi-System (Auth/ACL) and RuoYi-Robot Adapter (OpenAPI aggregation)
- Registry/Config: via Nacos (multi-environment)
- Data: MySQL (business data) and Redis (cache)
- Async: RabbitMQ (topic→queue→DLQ, manual-ack, idempotency)
- Observability: SkyWalking (trace/log/metrics stitched by traceId)
- Delivery: Docker Compose for multi-env one-click bring-up
4. Project Phases & Milestones¶
- Phase-1… (keep your original list; content unchanged, English wording aligned)
- Emphasize increments: gateway governance → async → observability → stability → delivery.
5. OpenAPI Wrapping & Stability Governance¶
Summary¶
| Module | Key points |
|---|---|
| Background / Pain | Vendor APIs have unstable RT/errors; upstream callers easily get dragged down. |
| Goals | Unify auth/retry/idempotency/trace; two-layer protection (Gateway + method level); read-mostly paths support cached fallback. |
| Design | GsOpenApiServiceImpl + @SentinelResource (resource names aligned with Nacos rules); Nacos-pushed Flow/Degrade rules; RestTemplate: timeouts/connection pool tuned, auto-retry disabled. |
| Trade-offs | Gateway vs. App who blocks first: relax Gateway limits in tests to observe breakpoints — prefer rate-limit first, then degrade/circuit-break as needed. |
Metrics & Results (examples)¶
| Metric | Target / Baseline | Notes |
|---|---|---|
| Burst handling | 429 fast-fail | Gateway/Sentinel returns immediately to protect downstream. |
| p95 latency | ‹value› ms | Fill with your test result; read-heavy paths should hit cache first. |
| Degrade policy | Last good data | Read endpoints return cached/snapshotted data (TTL-controlled). |
| Protection layers | Gateway first | Gateway rate-limit before app-level circuit-break; @SentinelResource as method-level safety net. |
| Retry/Timeout | Auto-retry disabled | RestTemplate connection/read timeouts and pooling to avoid cascades. |
Retro¶
- Rate-limit before circuit-break; unify error body/log fields for faster diagnosis.
Service Level Objectives (SLO)¶
Scope: Spring Cloud Gateway + Robot Service.
Window: 28 days (monthly).
Success definition: Count as success when the HTTP status is not 5xx and the businesscode==0; intentional 429 (rate limiting) is not counted as a failure and is tracked separately for capacity and threshold tuning.
Latency: by default, measure the duration from Gateway ingress → response sent.
📈 SLO (English)¶
1) SLO Table¶
| Journey / API | SLI | Target | Notes |
|---|---|---|---|
Status query GET /external/gs/status/** |
Success ≥ 99.9% | Monthly | Gateway rate-limit first; single-instance stable QPS × 0.7 headroom |
| P95 < 300ms (P99 < 800ms) | Monthly | Client typically retries with backoff 1–2 times | |
Map list GET /maps/list/** |
Success ≥ 99.9% | Monthly | Read-heavy; cache/replica |
| P95 < 400ms | Monthly | API baseline | |
Task dispatch (async acceptance) POST /external/gs/task/** |
Acceptance success ≥ 99.5% | Monthly (~3.6h budget) | Count success only if persisted + enqueued; idempotency key taskId |
| Acceptance P95 < 1s | Monthly | Synchronous “accepted” only; execution ACK not in this SLO | |
| WebSocket updates | Reconnect 99% < 3s | Monthly | Auto-reconnect; stale triggers alert |
2) SLI Definitions¶
- Success rate = (requests − HTTP 5xx − business failures) ÷ requests; business failure per unified
code. - Latency: P50/P95/P99 from gateway ingress to response; add service spans if needed.
- Async acceptance: HTTP 202/200 and persisted+enqueued = success (requires app metric).
- WebSocket recovery: disconnect to “receiving again” (heartbeat/subscription ack).
3) Protection thresholds (aligned with Sentinel)¶
- Slow-call threshold
τ = min(1000ms, 1.2 × current baseline P95) - Window 10s; minimum samples ≥ 20; slow-call ratio ≥ 50% → open circuit
- Open 30s; Half-open probes 5–10
- Ingress rate-limit on
/external/gs/**at Gateway (returns 429)
4) Alerting & Actions¶
- Error budget: 99.9% target ⇒ 0.1% monthly
- Burn rate alerts (either condition): 1h > 10% budget ⇒ P1 (auto degrade/limit); 6h > 20% ⇒ P1 escalate (rollback / remove unhealthy instance)
- Release guard: within 15min after release, if P95/P99 worsens and error > threshold ⇒ pause/rollback
- Traffic control: ramp Gateway quotas 5%→30%→50%→100%; if worse, staged circuit with stable fallback
5) Observability & Sources¶
SkyWalking traces/metrics; structured logs with traceId + 429/503/timeout fields; Nacos groups for rules with gray & rollback.
6) Exceptions¶
Execution SLA of long-running async tasks is out of scope here; external-network incidents are labeled for review, not forcibly excluded.